
BigQuery is a powerful data warehousing solution by Google that allows you to export Google Search Console and Google Analytics 4 data easily.
Many don’t know that what you get after is quite different from the API output.
The BigQuery tables are chaotic and hard to decipher without proper guidance.
I will explain to you how to clean those tables and combine the 2 datasets for SEO purposes.
Table of Contents
Exporting Data
Both GSC and GA4 have options to export the data and some room for customization.
I recommend following the official Google Documentation because it’s good:
You can navigate Google Search Console and see the option here:

Compile all the necessary fields and use names that are easy to recall:

Once it’s active, you will see something like this:

Google Analytics 4 has some additional options that make the process more confusing, as shown below:

What you select will affect the tables you will get in BigQuery:
The option below allows you to get daily exports and even data streamed as soon as it is available.
In most cases, Daily is the only option to pick as you don’t need to perform analysis every single day.

The Tables In BigQuery
BigQuery is the Google service storing the tables we need.
As some of you may recall, GA4 is using a user-centric model based on events and parameters.
This largely affects how we will work with this data and I recommend anyone to have a look (or remember) how Universal Analytics was different.
Google documentation is good and shows you the schema of the GSC and GA4 tables, namely how these tables look like.
I prepared an even better recap about the differences between GSC and GA4 in BigQuery compared to the UI/API.
I recommend spending more time on GA4 because GSC is much easier to understand.
If you need ready-to-use SQL code, you can get my free BigQuery handbook:
Google Search Console
The Bulk Export provides you with 2 tables:
- searchdata_site_impression
- searchdata_url_impression

The site table doesn’t double count impressions. If you have 2 pages ranking for a query, it will count as one impression.
Url contains the invaluable url column, a must-have for SEO because you want to know which pages brought traffic.
I have almost never used the site table because SEO analysis is often performed on pages and queries…
If you have to analyze entire GSC properties, then yes, you should use the site table!
N.B. The ExportLog is not a table and contains information on what was exported on a given day.
Reminder: GSC data include discover and news too. This is specified in the search_type column.
Google Analytics 4
Here comes the fun part, the tables you get depend on the options you selected when setting the linking process.
There are 4 tables at most:
- events_
- events_intraday_
- pseudonymous_users_
- users_
The 2 event tables record data for events and are what we will use. Actually, I will show you the most common use case, the events_ table.
The table named events_intraday_ only exists if you select to stream data.

As soon as new data is available, it’ll be added to that table.
The number in parentheses tell you which data are available.
(179) means the data from the previous 179 days is ready.
Neither I nor Google recommend querying that table because its data is incomplete.
Google explains the patterns of the events tables that get created, keep this in mind for later.

The 2 user tables contain valuable information about the users. This is important for marketing analysis but it’s not the first thing you will check as an SEO.
The first question I asked myself was: “Ok why are there 2 tables for each?”
If you have activated the User ID integration you will get the users_ table.
If your users can log in to your website, it means you have a chance to assign them a User ID.
In the majority of cases, you will just get the pseudonymous_users_ table though!
Nested Data
The real problem with the GA4 tables is that you have nested data.
Tidy data should have 1 value per cell, not many. Nested data is the opposite, there is more data in 1 single cell.
The example below will make it clearer:

What you see above is actually one row (1 event = 1 row) with its parameters, represented by the columns.
Some of these columns are records, so they store multiple values.
A record is a data type available in BigQuery.
The first_visit event has a ga_session_number equal to 1, the source is aol, the page_title is… etc.
It’s all information about one single event.
Pay particular attention to the event_params.key column as it stores what we need for analysis.
What we need is hidden inside the nested data so we need to unnest in SQL!
Cleaning Data
You MUST always clean data before you do any analysis.
This process often entails:
- Removing useless columns
- Filtering out pages you don’t need
- Filtering by the correct dimension(s)
Before you take any action, please remember to store a copy of your raw data in Google Cloud Storage.
It’s good advice to store your raw data somewhere in case something happens.
You can also store raw data in BigQuery, it’s not a problem in many cases.
How do you even know if the transformations you applied are correct? You need to save the raw data to make future comparisons.
GSC gives you many more columns than you need and many are boolean (i.e. they take on 2 values).

I have never used those fancy columns but you may need some depending on the website you are dealing with.
E.g. a cooking website may need to know about videos and recipe snippets.
In the majority of cases, you can drop most (if not all) of them.
Another important step is to remember to use the correct search_type in Search Console…
we usually don’t care much about Discover or News traffic for generic analyses.
All of these topics are also covered in my ebook in Python (or in my course), if you happen to work on smaller datasets (or want to use Python Notebooks in BigQuery).

Joining Tables
If you are doing SEO analysis, you want to unify tables and get a simple output.
The column for joining is always the URL you have in both events and url.
There are many types of joins…
You can either do a left or inner join.
I prefer going for a left join and using GSC as the left table.

This means that we are interested in getting the missing GA4 data (users, sessions, etc.) for all the URLs we can find in the GSC table.
So if GA4 has more URLs that don’t appear in GSC (e.g. noindexed pages), they will NOT be included.
You can also opt for an inner join:

In this case, only what’s in common with the GSC and GA4 data gets considered.
For example, if a page is only available in GA4 data (pages with utm parameters) but not in GSC, it won’t be considered for the new table.
There exists also the right join but no one uses it and it’s considered a joke.
This process isn’t easy for bigger datasets but it’s quick for normal websites.
The SQL Code
The SQL code below can be copied and pasted straight to BigQuery.
The picture below shows the crucial points in the BigQuery interface, head over QUERY and create a new one.
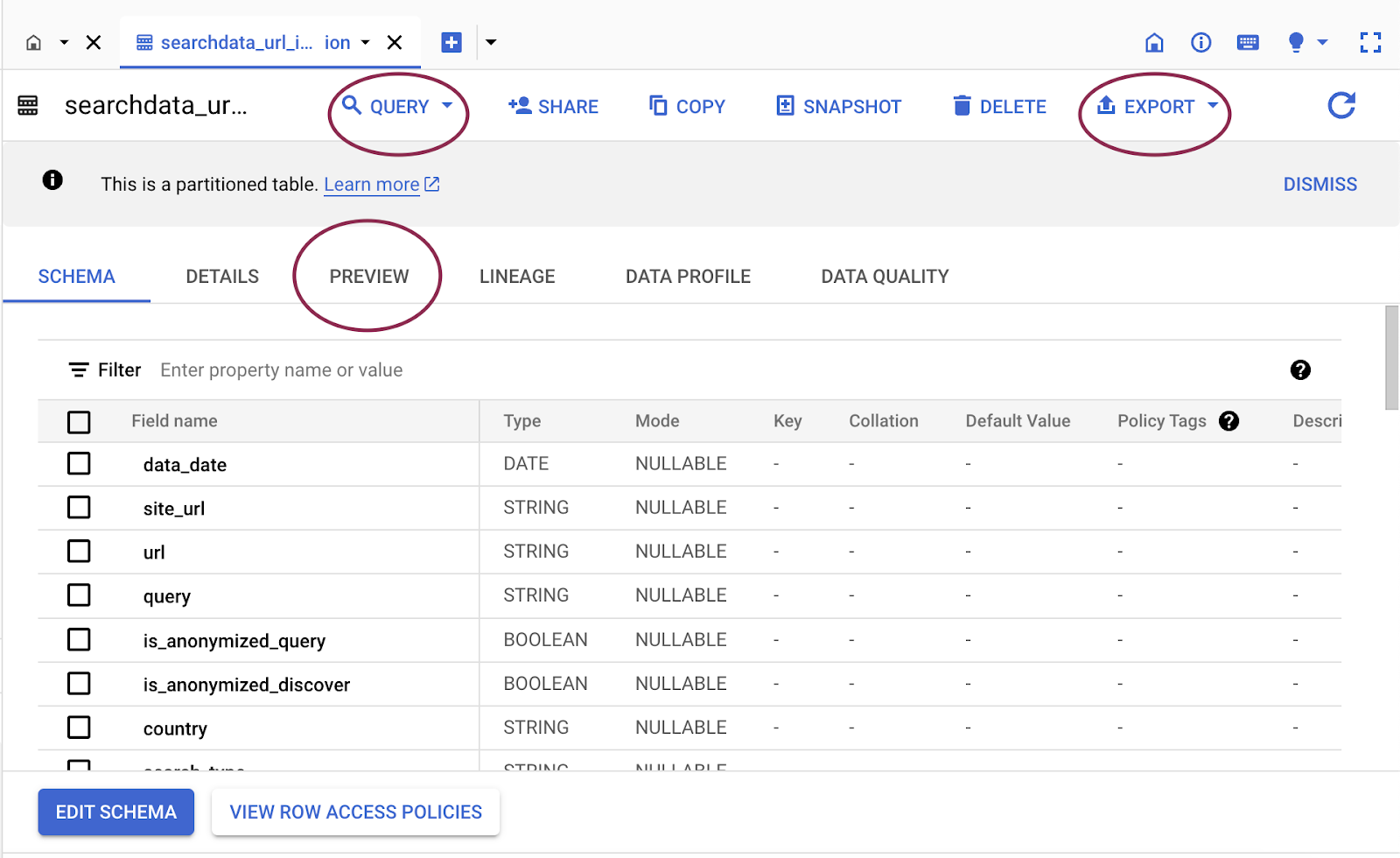
Before you paste the code below, please replace the correct sections of your code with the names of your datasets.
P.S. When using GA4 data, you have to change the naming of your table.
Use “events_*” as this shows BigQuery that you want to get all the tables following that pattern.
It’s important to use the quotes or BigQuery won’t be able to apply the wildcard.
You should have something like this:

(I got this wrong for weeks lol please check your quotes).
That’s because BQ stores one GA4 table per day, so you will need to use the pattern I just told you.
WITH ga4_data AS (
SELECT
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location') AS page_url,
COUNT(DISTINCT CONCAT(user_pseudo_id, (SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id'))) AS sessions,
COUNT(DISTINCT user_pseudo_id) AS users
FROM
`project_name.table_name.events_*` -- replace here
WHERE
_TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 YEAR)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
AND NOT REGEXP_CONTAINS((SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r'#')
GROUP BY
page_url
),
gsc_data AS (
SELECT
url AS page_url,
SUM(clicks) AS clicks,
SUM(impressions) AS impressions
FROM
`project_name.searchdata_url_impression` -- replace w/ GSC url table name
WHERE
data_date BETWEEN DATE_TRUNC(CURRENT_DATE(), YEAR) AND DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND search_type = 'WEB'
AND NOT CONTAINS_SUBSTR(url, '#')
GROUP BY
page_url
)
SELECT
gsc.page_url,
gsc.clicks,
gsc.impressions,
IFNULL(ga4.users, 0) AS users,
IFNULL(ga4.sessions, 0) AS sessions
FROM
gsc_data gsc
LEFT JOIN
ga4_data ga4
ON
gsc.page_url = ga4.page_url
ORDER BY
gsc.clicks DESC
What the code does: get 1 year of GSC and GA4 data that get combined together to show you a list of pages with their clicks, impressions, users, sessions and sorted by decreasing clicks.
If you want an inner join instead of the left join I just showed, replace the last part with:
FROM
gsc_data gsc
JOIN
ga4_data ga4
ON
gsc.page_url = ga4.page_url
ORDER BY
gsc.clicks DESCP.P.S. Your engineers may have changed naming conventions or even the tables you use (which is good).
Ask what they did in those cases!
Understanding The Code
The first part of the block is a CTE (Common Table Expression) and creates a temporary table holding the data we want.
From the events_ table, we unnest the values we need, filter by date and group by URL.
The UNNEST function is your best friend when unnesting data, keep that in mind.
We repeat a similar process for GSC url data.
Then, we select what we want in the final table and join the two CTE tables.
Reminder: if a page is available in GSC but not in GA4, you will get NULL values for users and sessions.
We use IFNULL to convert NULL values to 0 in case that happens. If you want to explicitly show NULL, just remove that function.
Do you see the _TABLE_SUFFIX_ string?
Yeah I struggled to understand it too, it’s just a way to filter our tables with a REGEX, and that’s why we appended the asterisk (*) at the end of the table name.
All of that expression filters the tables to be from yesterday to 1 year ago.
N.B. If you are testing the above code on a big website, ask an engineer first.
Big websites require efficiency and any wrong query can cost a lot of money.
The Output
The output should be something like this:

P.S. I censored the URLs before you ask.
You are now ready to create pivot tables and summarize the data.
BigQuery is a must-have for content auditing on big websites as you can’t open Excel and call it a day.
Even normal Python/R can’t compete against the power of SQL.
The idea is to have a Single Page View (SPV) that shows you all the important details for a given page:

Adding Queries (And More SQL)
As you may have noticed, adding queries can be problematic…

GA4 doesn’t tell us about users/sessions or any metrics by a specific query with the BQ linking.
So it’s impossible to get the correct contribution of each query unless you are fine with assumptions.
The picture above shows 1 URL with multiple queries and displays the same numbers for users and sessions.
If you ever plan on aggregating this data by page or query, avoid summing users and sessions together!!!
So if you want to get queries in a combined dataset, you can:
- Use GSC as your left table again and ignore what I said (be careful when aggregating rows)
- Have one column for queries, a row contains all the queries in a cell (nested data anyone?)
Ali Izadi shows a nice method for assigning a % to how much query contribute to total clicks in his article.
Mind you, in SEO we prioritize GSC data overall, be extremely careful when making assumptions about your data.
WITH ga4_data AS (
SELECT
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location') AS page_url,
COUNT(DISTINCT CONCAT(user_pseudo_id, (SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id'))) AS sessions,
COUNT(DISTINCT user_pseudo_id) AS users
FROM
`project_name.table_name.events_*`
WHERE
_TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 YEAR)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
GROUP BY
page_url
),
gsc_data AS (
SELECT
url AS page_url,
query,
SUM(clicks) AS clicks,
SUM(impressions) AS impressions
FROM
`project_name.searchdata_url_impression`
WHERE
data_date BETWEEN DATE_TRUNC(CURRENT_DATE(), YEAR) AND DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND search_type = 'WEB'
AND NOT CONTAINS_SUBSTR(url, '#')
GROUP BY
page_url, query
)
SELECT
gsc.page_url,
gsc.query,
gsc.clicks,
gsc.impressions,
IFNULL(ga4.users, 0) AS users,
IFNULL(ga4.sessions, 0) AS sessions
FROM
gsc_data gsc
LEFT JOIN
ga4_data ga4
ON
gsc.page_url = ga4.page_url
ORDER BY
gsc.page_url
What the code does: it’s the same code as before with the exception that you now get a query column and I sorted by URL.
You will most likely get NULL in page and query for the first row if you don’t filter by search_type because of Discover/News.
In fact, Google Discover/News don’t have any query and can have some anonymized data (so you won’t even see the page).
If you want a better and more BigQuery-like output, use:
WITH ga4_data AS (
SELECT
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location') AS page_url,
COUNT(DISTINCT CONCAT(user_pseudo_id, (SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id'))) AS sessions,
COUNT(DISTINCT user_pseudo_id) AS users
FROM
`project_name.table_name.events_*`
WHERE
_TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 YEAR)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
GROUP BY
page_url
),
gsc_data AS (
SELECT
url AS page_url,
ARRAY_AGG(STRUCT(query, clicks, impressions)) AS query_data
FROM (
SELECT
url,
query,
SUM(clicks) AS clicks,
SUM(impressions) AS impressions
FROM
`project_name.searchdata_url_impression`
WHERE
data_date BETWEEN DATE_TRUNC(CURRENT_DATE(), YEAR) AND DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND search_type = 'WEB'
AND NOT CONTAINS_SUBSTR(url, '#')
GROUP BY
url, query
)
GROUP BY
page_url
)
SELECT
gsc.page_url,
query_data,
IFNULL(ga4.users, 0) AS users,
IFNULL(ga4.sessions, 0) AS sessions
FROM
gsc_data gsc
LEFT JOIN
ga4_data ga4
ON
gsc.page_url = ga4.page_url
ORDER BY
gsc.page_urlIt should look like:

Now, this is much much better! I will probably go back to this section and update this article later.
P.S. We use page_location and ignore what is a landing page in GA4 because we want to get ALL of the missing data.
GSC is only about landing pages and we want to get that missing data that only page_location can provide.

2 Tables For The Win
In the majority of my projects, I have felt comfortable with this setup:

A Page-centric table follows the SPV approach so that you have all the page data you need (as already explained).
The original GSC url table is also fine because if you have query data, you must also look at pages!
Remember these splits when building dashboards because you want to avoid joining tables in tools like Looker Studio.
Some warnings and considerations
This process is OK for data analysis, meaning you will use it for a 1-time analysis or for reporting.
Data engineers should assist you and prepare a processed dataset with the most important columns you need.
There are no specific rules as the requirements will change from company to company.
I do NOT recommend tampering with the tables before saving a copy of the raw data.
Large websites follow different rules as there is a lot to optimize and worry about when using BigQuery.
The SQL code you run can be optimized extensively and even how you store the data.
Please, avoid copying and pasting code you use for small projects on large websites.
Toying With Tables
Google gives you the tables but they are far from ideal.
That’s understandable, it’s up to your organization to find what’s more suitable. There is no cookie-cutter solution here.
In some cases, you may want to unnest your GA4 data and split the original events table into multiple sub-tables.

Data modeling is a different beast and even the example above requires some tinkering and playing with transforming tables.
Otherwise, you can leave it as it is if you want to save storage. For more information, please consult this article on BigQuery storage optimization.
You could also precalculate some metrics so you don’t have to write SQL for them… but this practice isn’t always the best depending on how you aggregate data.
In most cases you don’t need to actually model the data, so I recommend to use existing solutions like:
- GA4Dataform (free tier)
- PipedOut (for medium companies with more specific needs)
Going Beyond Google Data
If you want to be serious about your work, you won’t stop at 2 data sources.
Big companies can do much more with their marketing data:
- Crawl data
- Log files
- Content plans
- Salesforce
- CRM
- CMS
There should be some solid reasons to integrate some data sources, like log files.

It can be quite expensive to pay for APIs like Semrush and Ahrefs and you need valid use cases to use them.
If you ask me, the best choices are the ones I listed and eventual 1st-party data at your disposal.
When combining tables, recall that your first choice is by page and the other possibilities are keywords (query) and dates/timestamps.
So far, BigQuery can help you get what’s in the top-right quadrant:

SEO Analysis is quite powerful in the right hands and even better if you forget about SEO as one single channel.
You can bring automation to the table and investigate in your data all from the comfort of one place.
Additional Resources – Learn More Now
If you still want to learn more, I recommend you read the following resources:
If you want to learn ALL and become a proficient Data Analyst, you can purchase my SEO Analytics course:

I go over a LOT of BigQuery to analyze both GSC and GA4 data and I keep updating it!